Run and monitor your own AI models behind the firewall. Cut GPU spend by up to 40% with autoscaling, idle detection, and real‑time FinOps — without cloud lock‑in or data risk.
No external APIs. No data egress. Your models, your VPC or on‑prem.
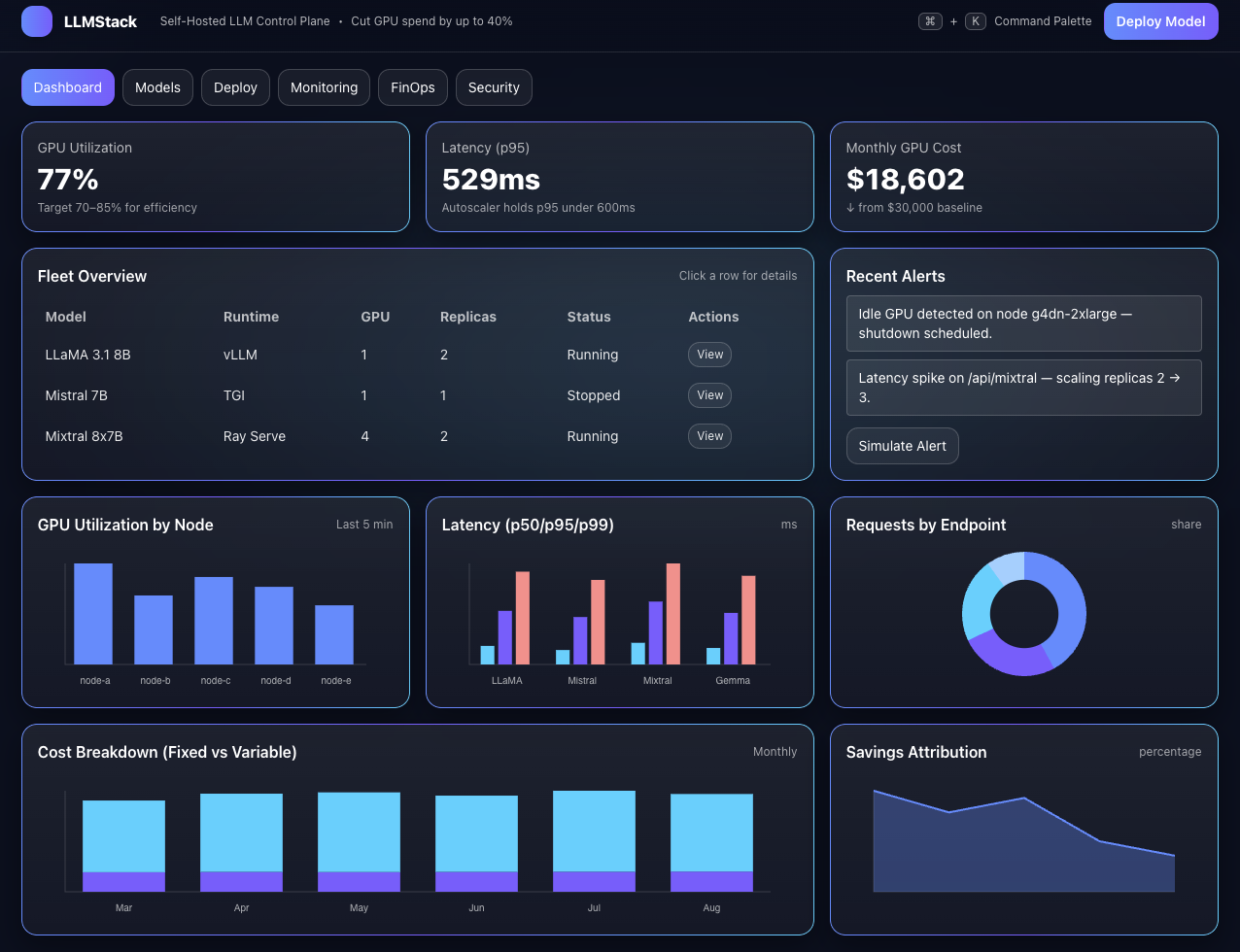
Visibility and automation prevent idle spend and over‑provisioning.
Prebuilt templates and a unified control plane beat DIY pipelines.
Everything you need to deploy, scale, observe, and save.
Deploy and manage LLaMA, Mistral, Mixtral, and more—with no DevOps headaches.
Auto‑scale GPU/CPU/RAM, detect idle instances, and route workloads smartly.
Real‑time spending, alerts, forecasting, and per‑team attribution.
Latency/throughput, resource utilization, error logs, and version history.
Self‑hosted, air‑gap, SSO/RBAC, audit logs, and zero persistent telemetry.
vLLM, TGI, Triton, Ray, Hugging Face—choose your stack.
Most teams overspend 20–50% on idle or mis‑allocated GPU capacity. LLM-Stack gives you the visibility and automation to eliminate waste in days — not quarters.
Auto‑shutdown for unused nodes. Wake on request to keep latency low.
Send inference to the most cost‑efficient node or runtime, automatically.
Per‑model & per‑team spend, alerts, and forecasting to prevent overruns.
Docker or Helm. Air‑gapped compatible. No external dependencies.
Use templates to launch LLaMA/Mistral with your preferred runtime.
Track cost/latency, scale intelligently, and enforce governance.
Supports vLLM, TGI, Triton, Ray, and Hugging Face stacks. Swap without rewriting your app.
# Docker (quick start)
docker run -d --name llmstack -p 8080:8080 ghcr.io/llmstack/llmstack:latest
# Helm (Kubernetes)
helm repo add llmstack https://charts.llmstack.dev
helm install llmstack llmstack/llmstack --namespace llmstack --create-namespace
# Authenticate (local admin)
llmstack login --host http://localhost:8080Replace registry/host as needed. Air‑gapped offline bundle available.
| Feature | LLM-Stack | Modal | Anyscale | RunPod | BentoML |
|---|---|---|---|---|---|
| Self‑hosted / Air‑gapped | ✅ | ❌ | ⚠️ | ❌ | ⚠️ |
| Pluggable runtimes | ✅ | ❌ | ✅ | ❌ | ✅ |
| Built‑in FinOps / cost savings | ✅ | ❌ | ⚠️ | ❌ | ❌ |
| No vendor lock‑in | ✅ | ❌ | ⚠️ | ❌ | ✅ |
| UI + API/CLI | ✅ | ✅ | ✅ | ⚠️ | ⚠️ |
Most teams recover the subscription via GPU savings in the first month.
$199/mo
💡 Offset 100% via idle GPU reductions.
$999/mo
💰 Typical savings: 20–40% within 30 days.
Contact for Pricing
📉 Savings compound with larger fleets.
“We stood up self‑hosted LLMs in days instead of months, and cut idle GPU spend by 38% in the first month.”
No. LLM-Stack is software that runs in your environment. Your data and models stay fully under your control.
vLLM, TGI, Triton, Ray, and others. Launch LLaMA, Mistral, Mixtral, Gemma, and more via templates.
Yes. No outbound telemetry by default and offline install options are available.
By preventing idle GPU spend, autoscaling capacity to match load, routing inference to lower‑cost nodes, and giving finance/engineering shared visibility with alerts and forecasting.
Tell us a bit about your use case and we’ll get back within one business day.